Afbeeldingen, data en AI: data verzamelen, data lezen
In 1743 publiceerde de Britse natuuronderzoeker Mark Catesby (1682/3-1749/50) zijn voorwoord voor The Natural History of Carolina, Florida and the Bahama Islands. Hij schreef:
“In designing the Plants, I always did them while fresh and just gather’d: And the Animals, particularly the Birds, I painted them while alive (except a very few) and gave them their Gestures peculiar to every kind of Bird, and where it would admit of, I have adapted the Birds to those Plants on which they fed, or have any Relation to. Fish which do not retain their Colours when out of their Element, I painted at different times, having a succession of them procur’d while the former lost their Colours: I dont pretend to have had this advantage in all, for some kinds I saw not plenty of, and of others I never saw above one or two : Reptiles will live many Months without Sustenance, so that I had no difficulty in Painting them while living.[i]
Deze passage geeft een bijzondere inkijk in Catesby’s werkwijze: die toont namelijk een vroegmoderne vorm van dataverzameling. Het ging het niet om het vangen van een levend dier, maar over het vastleggen van de (visuele) data van een diersoort. Catesby onderscheidde drie soorten waarneembare data die de artistieke output op papier bepaalden: vorm, omgeving en kleur. Ze lijken allemaal vanzelfsprekend, maar hij wees nadrukkelijk op één probleem: kleuren vervagen.
Synthetische data – ervaringsdata?
Ik moest aan deze passage denken tijdens een seminar in juli (Toolkit for Today: Computation is the new Optics) georganiseerd door het Canadian Centre for Architecture in Montréal, waar ik de afgelopen zomer als een doctoral resident verbleef. Die week stond in het teken van systemen: structuren die de wereld ordenen en leesbaar maken, vaak ten behoeve van macht en controle.
Deze zijn niet los te koppelen van technologische ontwikkelingen en gaan vandaag de dag, in een door algoritmes en artificiële intelligentie (AI) gedomineerde wereld, over wat computersystemen zien en ons teruggeven. AI gaat uit van synthetische data – (kunstmatig) gegenereerde gegevens die een basiswerkelijkheid vormen voor het syteem – en laat daarbij ontologische, culturele en andere contextuele vooroordelen buiten beschouwing om de output te presenteren als objectief.

Afb. 1. Mark Catesby, “The Lane-Snapper” [Lutjanus synagris], ca. 1722-1726. Courtesy of Royal Collection Enterprises Limited 2025 | Royal Collection Trust, London.
Catesby observeerde, maakte notities en tekende op basis van deze ervaringsgegevens. Dit lijkt heel anders dan hoe AI met synthetische data werkt. Toch bracht ook Catesby, bewust of onbewust, zijn eigen basiswerkelijkheid met zich mee tijdens het verzamelen. Hij synthetiseerde de data van al zijn waarnemingen tot één voorbeeldvis, waarbij de individualiteit van de vissen verloren is gegaan.
Hoewel een vergelijking tussen de verzamelmethoden van Catesby en AI-systemen misschien vergezocht lijkt, gebeurt er bijna hetzelfde. In zijn essay beschrijft Catesby welke visuele data hij heeft gebruikt voor zijn afbeelding (Afbeelding 2). Als we een AI-systeem eenzelfde afbeelding van een “Lane-Snapper” laten genereren, is echter veel minder inzichtelijk op basis van welke data die afbeelding tot stand is gekomen.[iii] Maar in beide gevallen worden data met een basiswerkelijkheid gesynthetiseerd.
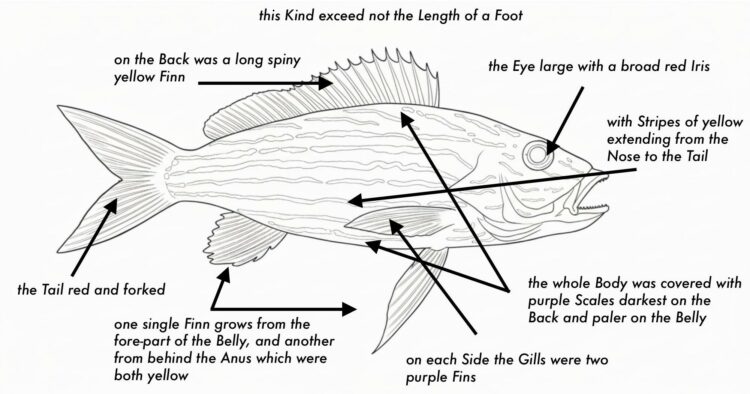
Afb. 2. Afbeelding gegenereerd door Google Gemini 2.5 Flash, Nano Banana, 17 september 2025, naar Mark Catesby’s “The Lane-Snapper”, prompt: “Can you transform this image into a sharp black-and-white outline drawing, as a coloring plate?”. Tekst (uit Catesby, The Natural History, deel 2, pl. 17) en pijlen aangebracht door auteur.
Catesby’s afbeelding, het bijbehorende essay en de geciteerde passage laten zien dat het synthetiseren van data – of het nu om ervaringsgegevens of gegenereerde data gaat – altijd een proces is van invullen, samenvoegen en inkleuren op basis van de basiswerkelijkheid van het systeem. Ter vergelijking heb ik ChatGPT DeepResearch 5 ook een “Lane-Snapper” laten maken, puur op basis van Catesby’s essay (Afbeelding 3).

Afb. 3. Afbeelding gegenereerd door ChatGPT DeepResearch 5, OpenAI, 7 oktober 2025, prompt: “Create an image of a “Lane-Snapper” based on the following information: [essay Catesby, “The Lane-Snapper”, The Natural History, deel 2, pl. 17]”.

Afb. 4. National Oceanic and Atmospheric Administration. U.S. Department of Commerce; SEFSC Pascagoula Laboratory; Collection of Brandi Noble, “fish4318. Lane snapper (Lutjanus synagris). Gulf of Mexico”, undated. Courtesy of Wikimedia Commons.

Afb. 5. Afbeelding gegenereerd door ChatGPT DeepResearch 5, OpenAI, 7 oktober 2025, prompt: “Now update this image, but update your ground truth so that it includes knowledge that you’re supposed to create a lane snapper (lutjanus synagris)”.
Een dergelijk experiment lijkt triviaal geklooi met moderne techniek. Niets is minder waar. Dit laat op een eenvoudige manier zien hoe afbeeldingen in elkaar steken, of ze nu in de achttiende eeuw gemaakt zijn door een natuuronderzoeker of door een computersysteem met toegang tot een oneindige hoeveelheid aan data. Het analyseren van de manier waarop afbeeldingen worden samengesteld, helpt ons nadenken over de ware betekenis van auteurschap in een tijd waarin technologie zo een grote rol speelt.
[i] Mark Catesby, The Natural History of Carolina, Florida and the Bahama Islands […], twee delen en een appendix (Londen: geprint op kosten van de auteur, 1731-1743 [1729-1747]), deel 1, xi.
[ii] Mark Catesby, “The Lane-Snapper”, ca. 1722-1726. Aquarel over potlood, 17,1 x 33,5 cm, vel papier. Royal Collection Trust, Londen: RCIN 925961.
[iii] Gesprek tussen auteur en ChatGPT DeepResearch 5, “Create lane snapper image”, OpenAI, 7 oktober 2025, https://chatgpt.com/share/68e50bc0-6b30-8012-9fb8-4ee6583c204a.
[iv] Gesprek tussen auteur en ChatGPT DeepResearch 5, “Image creation description”, OpenAI, 7 oktober 2025, https://chatgpt.com/share/68e51921-8824-8012-b349-4945906b72fe.